During the Developer Days presentation, in one of the discord chats, someone mentioned having created a solution in PowerBI to pull data from IDN and relate it so that it could be used for audit reporting. If that was you, please post details here.
Hey Jodi,
Welcome to the SailPoint Developer Community—I hope you enjoyed Developer Days! I did some sleuthing in the Discord chat for you and cross-referenced the user. It looks like it was @mcheek.
Mark, any chance you can expand on the PowerBI reports you did using the IdentityNow API?
Thank you for tracking this down!
The trickiest part is that Power BI’s “Web” source does not allow oauth-type authentication, only basic and api key-based auth.
In order to get around this, I had to create a “Blank Query” and do everything in Power Query.
Here are some of the snippets…
First, you need to get a token using your client credentials
getToken = Json.Document(
Web.Contents(
param_root_uri,
[
RelativePath="/oauth/token",
Query=[
grant_type="client_credentials",
client_id=param_client_id,
client_secret=param_client_secret
],
Content=Text.ToBinary("hi")
]
)
)
Notice that I had my root uri, client id and client secret in parameters

Also, if I recall correctly, the method to get a token requires a POST. The only way to make Power BI do a POST using Web.Contents is to give it some content, which is why I have that line
Content=Text.ToBinary("hi")
This particular query is hitting the /v3/search endpoint, which if you recall has a 250 document limit, so you have to paginate. I’m going to do a couple steps out of order here. First, here is the “loop” function that helps paginate through the results
results = List.Generate(
() => [Offset = 250, identities = getIdentities(0)],
each not (List.IsEmpty([identities])),
each [ identities = getIdentities( [Offset] ),
Offset = [Offset] + 250 ],
each [identities]
)
Then the actual function being called
getIdentities = (Offset) =>
let docs = Json.Document(
Web.Contents(
param_root_uri,
[
RelativePath="/v3/search",
Headers=[
#"Authorization"=authToken,
#"Content-Type"="application/json"
],
Query=[
limit = "250",
offset = Number.ToText(Offset)
],
Content=Text.ToBinary("{ ""indices"": [ ""identities"" ], ""query"": { ""query"": ""(attributes.cloudLifecycleState:active OR attributes.cloudLifecycleState:legalHoldActive OR attributes.cloudLifecycleState:prehire OR attributes.cloudLifecycleState:rehire) AND identityProfile.name:\""Mulesoft Profile\"""" }, ""queryResultFilter"":{ ""includes"": [ ""id"",""displayName"", ""employeeNumber"", ""manager.displayName"", ""manager.name"", ""access.id"", ""access.type"", ""access.displayName"", ""access.description"", ""access.privileged"", ""access.source.name"",""access.source.id"",""access.value"" ] },""sort"": [ ""id"" ]}")
]
)
)
in docs
The particular search being run above is pulling back identities that are active and have a specific identity profile.
Ok, let’s put it all together
let
getToken = Json.Document(
Web.Contents(
param_root_uri,
[
RelativePath="/oauth/token",
Query=[
grant_type="client_credentials",
client_id=param_client_id,
client_secret=param_client_secret
],
Content=Text.ToBinary("hi")
]
)
),
token = getToken[access_token],
authToken = "bearer " & token,
getIdentities = (Offset) =>
let docs = Json.Document(
Web.Contents(
param_root_uri,
[
RelativePath="/v3/search",
Headers=[
#"Authorization"=authToken,
#"Content-Type"="application/json"
],
Query=[
limit = "250",
offset = Number.ToText(Offset)
],
Content=Text.ToBinary("{ ""indices"": [ ""identities"" ], ""query"": { ""query"": ""(attributes.cloudLifecycleState:active OR attributes.cloudLifecycleState:legalHoldActive OR attributes.cloudLifecycleState:prehire OR attributes.cloudLifecycleState:rehire) AND identityProfile.name:\""Mulesoft Profile\"""" }, ""queryResultFilter"":{ ""includes"": [ ""id"",""displayName"", ""employeeNumber"", ""manager.displayName"", ""manager.name"", ""access.id"", ""access.type"", ""access.displayName"", ""access.description"", ""access.privileged"", ""access.source.name"",""access.source.id"",""access.value"" ] },""sort"": [ ""id"" ]}")
]
)
)
in docs,
results = List.Generate(
() => [Offset = 250, identities = getIdentities(0)],
each not (List.IsEmpty([identities])),
each [ identities = getIdentities( [Offset] ),
Offset = [Offset] + 250 ],
each [identities]
)
in
results
From there, you convert it to a table, expand columns, etc
@mcheek to the rescue—you should have been a speaker at Developer Days 2023! Maybe 2024?!
Hah perhaps…
While it’s possible to extract this data into Power BI, taking a bunch of document-oriented data and modeling it in a more “traditional” relational/tabular format takes a lot of work, and there are some Power BI specific workarounds required to make it all work. For example, you cannot make a “join” using more than one join key in Power BI, you must concatenate your two join keys together into their own custom column, and then remember that’s why you did that.
In the future, I’d like to look into ingesting this data into our data warehouse so that the modeling can be done using SQL and then just have Power BI pull directly from views that we model.
@colin_mckibben if I may provide a bit of feedback on this that I feel is too specific to put into the ideas portal…
Specifically, if you are using /v3/search to query identities, the access sub-collection in the document does not include a reference to the account assigned to an entitlement.
This isn’t really an issue if for each source, an identity will only have a single account in that source, and you can keep a 1:many cardinality between accounts and entitlements within a given source.
However, this goes out the window if an identity has more than one account in a source. This isn’t that uncommon, as many orgs want users with elevated access to have that access assigned to an elevated account with credentials separate from their normal account.
If a person has more than one account in a source, suddenly the cardinality between accounts and entitlements changes to many:many, and you cannot get an accurate representation of what entitlements belong to which accounts.
The solution with the current identity “schema” would be have some sort of for-each function that runs on each row returned that plugs the account Id into an additional query that hits /v3/accounts/{id}/entitlements, but this isn’t very simple to do with PowerBI, and it’s more complicated than it should be.
Does what I’ve explained make sense?
@colin_mckibben let me expand a bit on my post above with some visual examples.
My use case here is to show all identity accounts and their associated entitlements in a single table
For the first table, I get accounts associated with an identity using this query against /v3/search
{
"indices": [
"identities"
],
"query": {
"query": "attributes.uid:mcheek"
},
"queryResultFilter": {
"includes": [
"id",
"accounts.source.id",
"accounts.source.name",
"accounts.name",
"accounts.id"
]
},
"sort": [
"id"
]
}
That results in the table you see below. Note I have created a custom column concatenating the identity Id and the account source Id to use as a join key

Next, I’ll pull all my access using the same query but returning different values
{
"indices": [
"identities"
],
"query": {
"query": "attributes.uid:mcheek"
},
"queryResultFilter": {
"includes": [
"id",
"access.displayName",
"access.source.name",
"access.source.id"
]
},
"sort": [
"id"
]
}
That results in this table. Again, I have created a custom column concatenating the identity Id and Source Id of the entitlement

When I tell Power BI that I want to create a join relationship between those two tables, it correctly identifies the cardinality as 1:many between accounts and access

Let’s look at another user who has two accounts with their own entitlements in a single source

You’ll see in his access that he has 3 entitlements in that source, with two duplicate rows because both accounts have a common entitlement

When I attempt to join these two tables, it correctly identifies the cardinality as many:many

The result is that it incorrectly shows the CHENRY account has the entitlement Security

When you look at his accounts in the JSON, that’s not correct
{
"privileged": false,
"accountId": "adm_chenry",
"entitlementAttributes": {
"Role": [
"Security",
" System Administrators Only"
]
},
"created": "2022-07-07T13:39:01.123Z",
"name": "adm_chenry",
"disabled": false,
"id": "2c9180858191a33b0181d8e2a58337e4",
"source": {
"name": "Enertia",
"id": "2c91808481d42b010181d8d5e6656219",
"type": "JDBC"
},
"locked": false,
"manuallyCorrelated": true
},
{
"privileged": false,
"accountId": "CHenry",
"entitlementAttributes": {
"Role": [
" System Administrators Only"
]
},
"created": "2022-07-07T13:39:01.875Z",
"name": "CHenry",
"disabled": false,
"id": "2c9180858191a33b0181d8e2a8732cb5",
"source": {
"name": "Enertia",
"id": "2c91808481d42b010181d8d5e6656219",
"type": "JDBC"
},
"locked": false,
"manuallyCorrelated": false
}
This is due to the fact that the access sub-collection doesn’t have a reference to which account is assigned an entitlement.
{
"privileged": false,
"displayName": "Security",
"name": "Security",
"standalone": true,
"id": "2c9180838191a33a0181d8e2a9ea24bd",
"source": {
"name": "Enertia",
"id": "2c91808481d42b010181d8d5e6656219"
},
"attribute": "Role",
"type": "ENTITLEMENT",
"value": "Security"
}
If the schema could be updated to do something as simple as this
{
"privileged": false,
"displayName": "Security",
"name": "Security",
"standalone": true,
"id": "2c9180838191a33a0181d8e2a9ea24bd",
"source": {
"name": "Enertia",
"id": "2c91808481d42b010181d8d5e6656219"
},
"attribute": "Role",
"type": "ENTITLEMENT",
"value": "Security",
"account": {
"name": "adm_chenry",
"id": "2c9180858191a33b0181d8e2a58337e4"
}
}
That would solve this issue
Thanks, Mark.
What does the resulting final report look like? Can it produce the user name, job title, roles, access profiles and entitlements all on one report (and with the descriptive attributes – not the UIDs)?

@mcheek I went ahead and submitted an idea for this: https://ideas.sailpoint.com/ideas/GOV-I-2386
I think there might be a workaround in the meantime.
- Import the identities that only have one account, since your solution works perfectly fine for those identities.
- Identify the identities that have more than one account. You can use this search query to find them: Get Users With More Than One Account in the Same Source - #7 by colin_mckibben
- Use the get account entitlements API to correctly map which entitlements belong to each account for the identity. You can probably just modify the access data you get from the identity search to include the account reference object that you want to see.
Yes, I had thought of using that API endpoint to get the entitlement data I need. The issue is that it requires I do a sort of “for-each” type function on the accounts I pull in to query that endpoint for each account that is returned, and add those entitlements as their own column.
I don’t know how to perform such a function in Power BI (although I’ve been researching) and I would argue that many others don’t either, so it makes some aspects of reporting inaccessible for the vast majority of people out there.
Appreciate you posting this information.
Have you encountered the 10k limit using this method? The API discusses using the searchAfter, to get around this limit.
Do you possible have an example of this?
Hey Steve,
I haven’t run into a need for this yet, but I assume it will be sooner rather than later with the pace account activities get created.
@mcheek A novice question: I’m new to PowerBI and Power Query, unsure on how I can execute this blank query you’ve created. Once the parameters and the query are populated, how do I execute it (from the Power Query Editor UI)?
There should be a button to refresh the data preview which will bring back the first few hundred rows or something
When I refresh data, it says ‘1 row loaded’, but I don’t even see the row it loaded.
Also the language of this query looks like JS but it is Power Query M language right? (Had me confused for a second there!)
Is there a way I can check if the query failed or something along those lines to debug? Right now I’m using the same v3 search API call you have, but my IDN search query is just an asterisk (*).
Typically if there was an error either from the IdN API or in your PBI query it would tell you.
How many identities do you have in your environment? My query pulls back just under 2000 identities, so I have 8 “List” rows that contain up to 250 records each
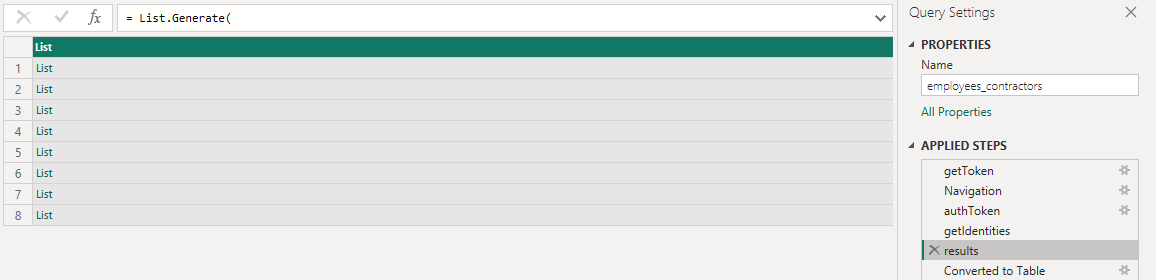
From there I have to convert it to a table, then expand each list to new rows

Then expand each individual column where I want one of the values that’s in a json object
What does yours look like?
Also @sushantkulkarni happy cake day
I have over 3000 identities in the tenant at the moment. I just wanted to see some data flow in so I kept the IDN query as generic as it gets, just a ‘*’.
I had my query put in this box at the top here (it auto-adds the encoding for new lines like CRLF):

I could see a preview of the query just below the text box too. Next, I click on Refresh Preview (Note that the parameters have all been initialized with the right values at this point):

Nothing happens, not even an error message. So I just close and apply, and from the main PowerBI UI, I click refresh. That’s where I see 1 row loaded:

I don’t see anything loaded anywhere. Here’s your blank query but with just one change, the IDN query being an asterisk. Let me know if you see an issue here:
let getToken = Json.Document(
Web.Contents(
param_root_uri,
[
RelativePath="/oauth/token",
Query=[
grant_type="client_credentials",
client_id=param_client_id,
client_secret=param_client_secret
],
Content=Text.ToBinary("hi")
]
)
),
token = getToken[access_token],
authToken = "bearer " & token,
getIdentities = (Offset) =>
let docs = Json.Document(
Web.Contents(
param_root_uri,
[
RelativePath="/v3/search",
Headers=[
#"Authorization"=authToken,
#"Content-Type"="application/json"
],
Query=[
limit = "250",
offset = Number.ToText(Offset)
],
Content=Text.ToBinary("{ ""indices"": [ ""identities"" ], ""query"": { ""query"": ""*"" }, ""queryResultFilter"":{ ""includes"": [ ""id"",""displayName"", ""employeeNumber"", ""manager.displayName"", ""manager.name"", ""access.id"", ""access.type"", ""access.displayName"", ""access.description"", ""access.privileged"", ""access.source.name"",""access.source.id"",""access.value"" ] },""sort"": [ ""id"" ]}")
]
)
)
in docs,
results = List.Generate(
() => [Offset = 250, identities = getIdentities(0)],
each not (List.IsEmpty([identities])),
each [ identities = getIdentities( [Offset] ),
Offset = [Offset] + 250 ],
each [identities]
)
in results