Transform Rule
Overview
This rule type is used in transforms to accomplish a specific task given configurable parameters described in the transforms attributes. The rule to perform the same task as the split transform given a delimiter and index would look like this:
Transform
{
"name": "Split Rule",
"type": "rule",
"attributes": {
"name": "Split",
"delimiter": ",",
"index": 0,
"text": "This,is,a,test"
}
}
Rule Code
The variables delimiter, index, and text in the above transform are all available to you within the scope of the rule.
String delimiter = delimiter;
int index = index;
String text = text;
String[] result = text.split(delimiter);
return result[index];
Execution
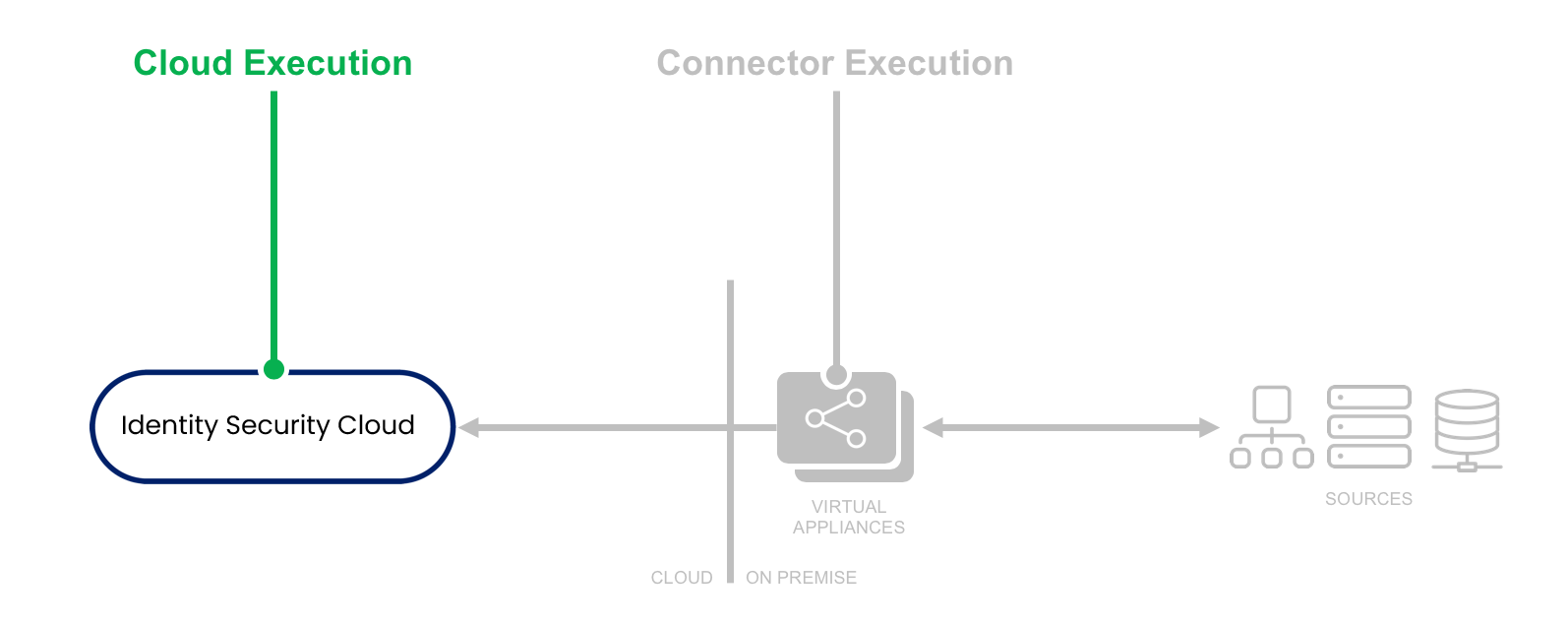
- Cloud Execution - This rule executes in the Identity Security Cloud cloud, and it has read-only access to Identity Security Cloud data models, but it does not have access to on-premise sources or connectors.
- Logging - Logging statements are currently only visible to SailPoint personnel.
Input
| Argument | Type | Purpose |
|---|---|---|
| log | org.apache.log4j.Logger | Logger to log statements. Note: This executes in the cloud, and logging is currently not exposed to anyone other than SailPoint. |
| idn | sailpoint.server.IdnRuleUtil | Provides a read-only starting point for using the SailPoint API. From this passed reference, the rule can interrogate the Identity Security Cloud data model including identities or account information via helper methods as described in IdnRuleUtil. |
Output
| Argument | Type | Purpose |
|---|---|---|
| value | java.lang.Object | Value returned for the account attribute, typically a string. |
Template
warning
The type attribute is now required on the <Rule> element. You must specify type="Transform" going forward. In previous versions, this attribute could be omitted.
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE Rule PUBLIC "sailpoint.dtd" "sailpoint.dtd">
<Rule name="Example Rule" type="Transform">
<Description>Describe your rule here.</Description>
<Source><![CDATA[
// Add your logic here.
]]></Source>
</Rule>
Example - Name Normalizer
This rule normalizes any names into normal names capitaliztion. For example: JOHN DOE -> John Doe.
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE Rule PUBLIC "sailpoint.dtd" "sailpoint.dtd">
<Rule name="Name Normalizer" type="Transform">
<Description>
This rule normalizes any names into normal names capitaliztion. For example:
JOHN DOE -> John Doe
tony smith -> Tony Smith
CORNELIUS AUGUSTINE MCGLENNON IV -> Cornelius Augustine McGlennon IV
NEIL MC GLENNON -> Neil McGlennon
mArTiN o'mAlLeY -> Martin O'Malley
Dr. JOHN D. O'BRIEN -> Dr. John D. O'Brien
john wilkes-booth -> John Wilkes-Booth
JOAN OF ARC -> Joan of Arc
MACKENNA -> MacKenna
OSCAR DE LA HOYA -> Oscar de la Hoya
CAPTAIN VON TRAPP -> Captain von Trapp
Dell dEl Roach -> Dell del Roach
Augustiner Anstruther-Gough-Calthorpe -> Augustiner Anstruther-Gough-Calthorpe
GEORGE HENRY LANE-FOX PITT-RIVERS ESQ. -> George Henry Lane-Fox Pitt-Rivers Esq.
JOSÉ ORTEGA Y GASSET -> José Ortega y Gasset
</Description>
<Source><![CDATA[
import java.util.Iterator;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.commons.lang.StringUtils;
import org.apache.commons.lang.WordUtils;
import com.google.gson.Gson;
/*
* Delimiter Constant (Step 2): These define default word boundaries for the 'capitalizeFully' function.
* Default is hyphenated last names, space, and anything with ' character.
*/
char[] delimiters = delimiters;
/*
* Patterns Constant (Step 3): These are for special replacements for Mc and Mac surnames.
*/
String patterns = patterns;
/*
* Replacements Constant (Step 4): These are for special replacements for titles, suffixes, and name linkages.
*/
String replacements = replacements;
/*
* Normalize Name Function
* Input: String
* Output: String
*/
public String normalizeName ( String input ) {
/*
* Step 1: If we're null or empty, we're done.
*/
input = StringUtils.trimToNull( input );
if ( input == null )
return null;
/*
* Step 2: Iterate through delimiters, and do a pattern match on capitalizaion. This takes care of 99% of the simple stuff.
* e.g. john doe -> John Doe
*/
input = WordUtils.capitalizeFully( input, delimiters );
/*
* Step 3: Iterate through and handle special cases.
* e.g. Mcglennon -> McGlennon, Mackenna -> MacKenna
*/
Matcher m = Pattern.compile( patterns ).matcher( input );
while ( m.find() ) {
input = WordUtils.capitalizeFully( input.substring( 0, m.start() ), delimiters )
+ WordUtils.capitalizeFully( input.substring( m.start(), m.end() ), delimiters )
+ WordUtils.capitalizeFully( input.substring( m.end(), input.length() ), delimiters );
}
/*
* Step 4: Iterate through special replacement exceptions.
* e.g. CAPTAIN VON TRAPP -> Captain Von Trapp -> Captain von Trapp
*/
Map replaceMap = new Gson().fromJson( replacements, Map.class );
Iterator it = replaceMap.entrySet().iterator();
while (it.hasNext()) {
Map.Entry pair = (Map.Entry) it.next();
input = Pattern.compile( (String) pair.getKey() ).matcher( input ).replaceAll( (String) pair.getValue() );
it.remove(); // avoids a ConcurrentModificationException
}
/*
* We're done!
*/
return input;
}
return normalizeName( input );
]]></Source>
</Rule>
Transform Reference
{
"name": "Normalize Name",
"type": "rule",
"attributes": {
"name": "Name Normalizer",
"delimiters": ["-", " ", "\\'"],
"replacements": {
"\\\\b(?:Von)\\\\b": "von",
"\\\\b(?:Del)\\\\b": "del",
"\\\\b(?:Of)\\\\b": "of",
"\\\\b(?:De)\\\\b": "de",
"\\\\b(?:La)\\\\b": "la",
"\\\\b(?:Y)\\\\b": "y",
"\\\\b(?:Iv)\\\\b": "IV",
"\\\\b(?:Iii)\\\\b": "III",
"\\\\b(?:Ii)\\\\b": "II",
"\\\\b(?:Mc )\\\\b": "Mc"
},
"patterns": "\\b(Mc|Mac)",
"input": {
"type": "trim"
}
}
}